Simulation and evaluation
studio for voice agents
Run simulations with realistic user personas for key scenarios and evaluate every component of your voice agent to ship with confidence
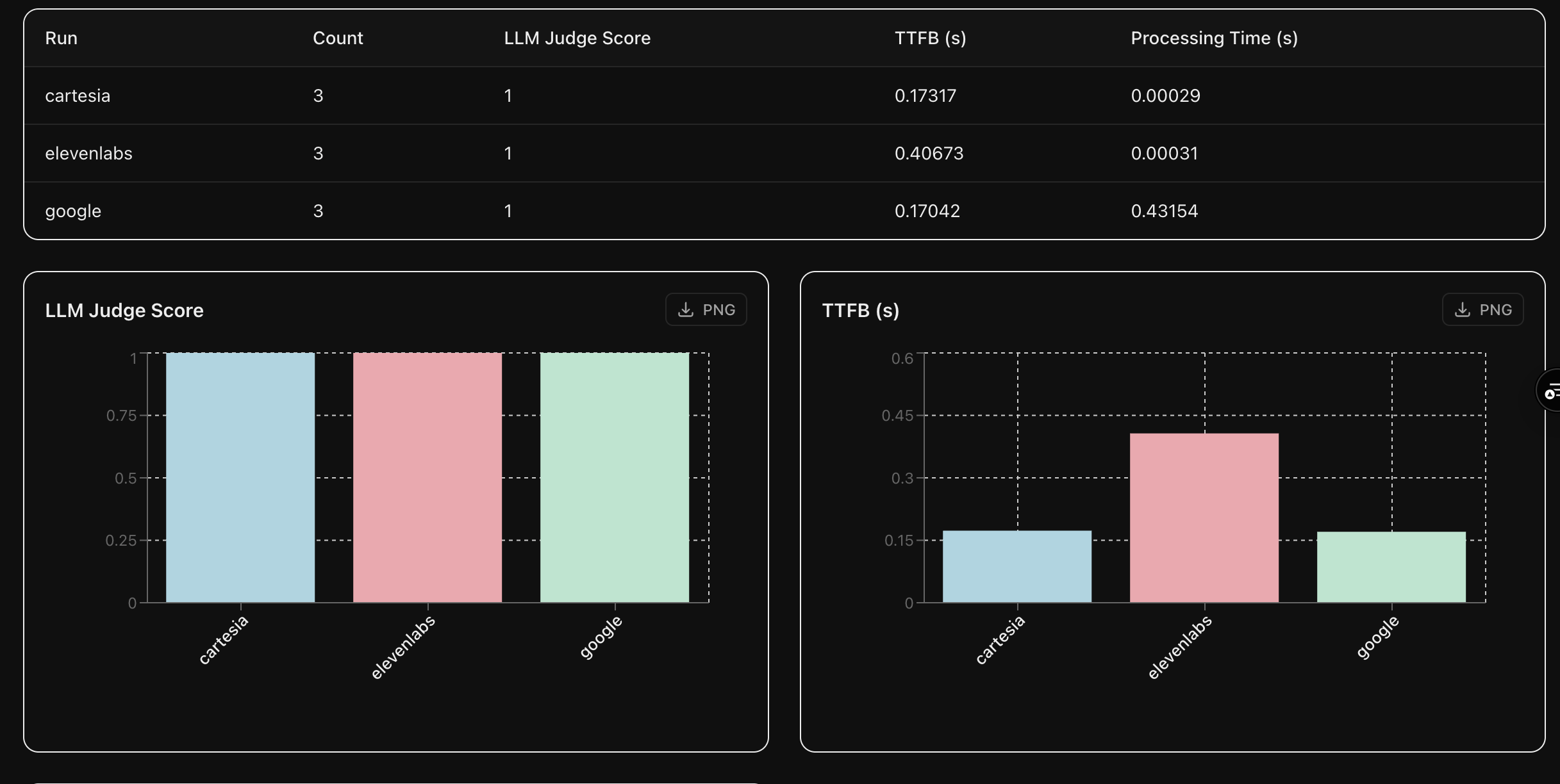
Benchmark providers to find the best fit for your use case
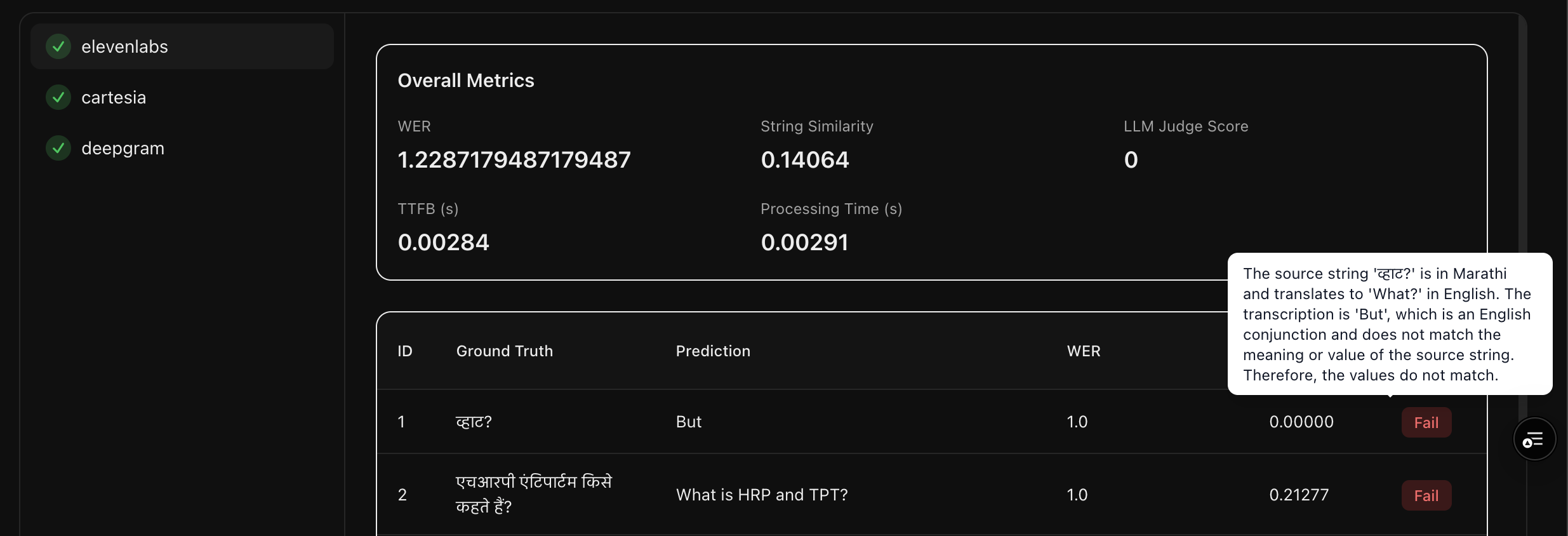
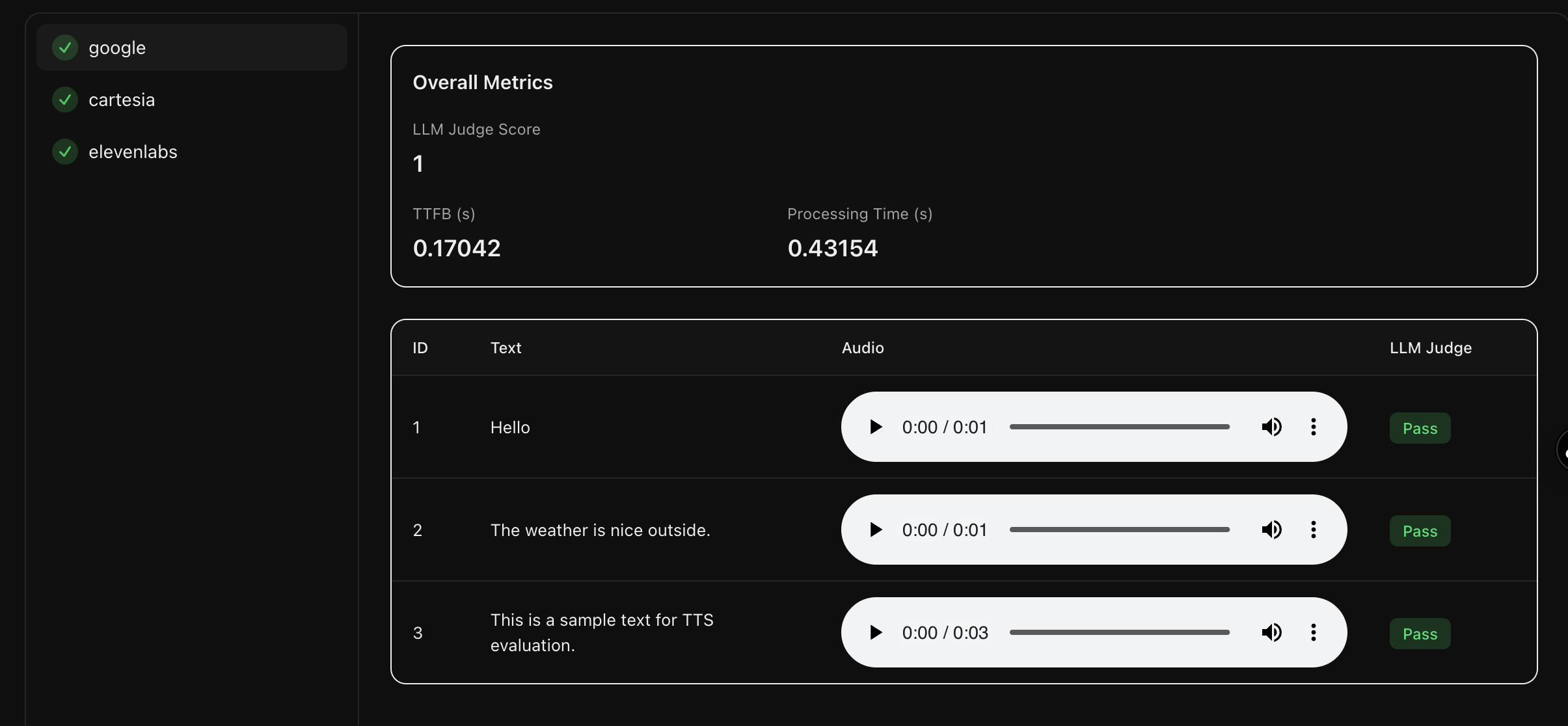
Go beyond simplistic rule-based metrics towards accurate evaluations by comparing the meaning of the transcriptions with the reference texts
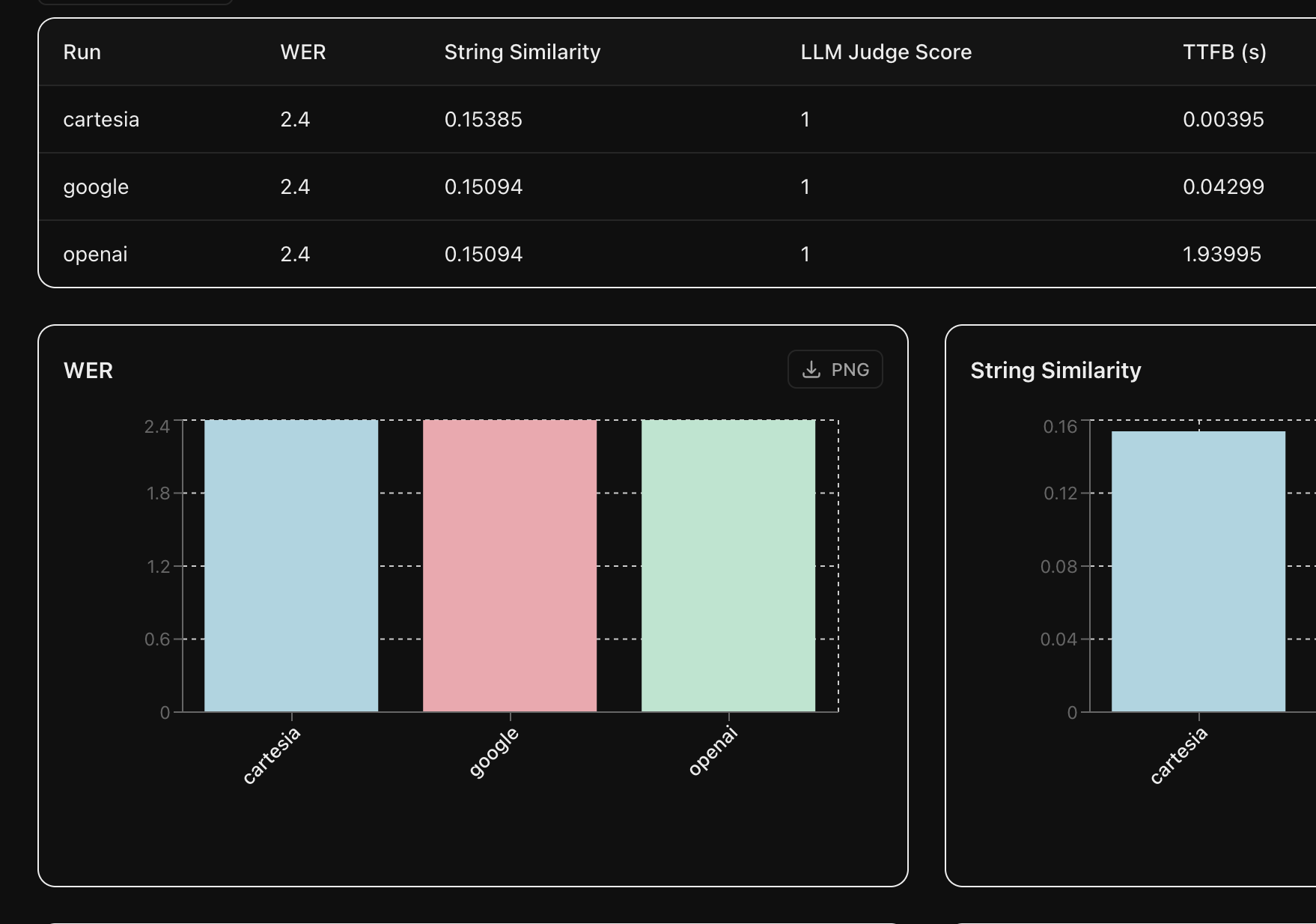
Benchmark providers to find the best fit for your use case
Go beyond simplistic rule-based metrics towards accurate evaluations by comparing the meaning of the transcriptions with the reference texts
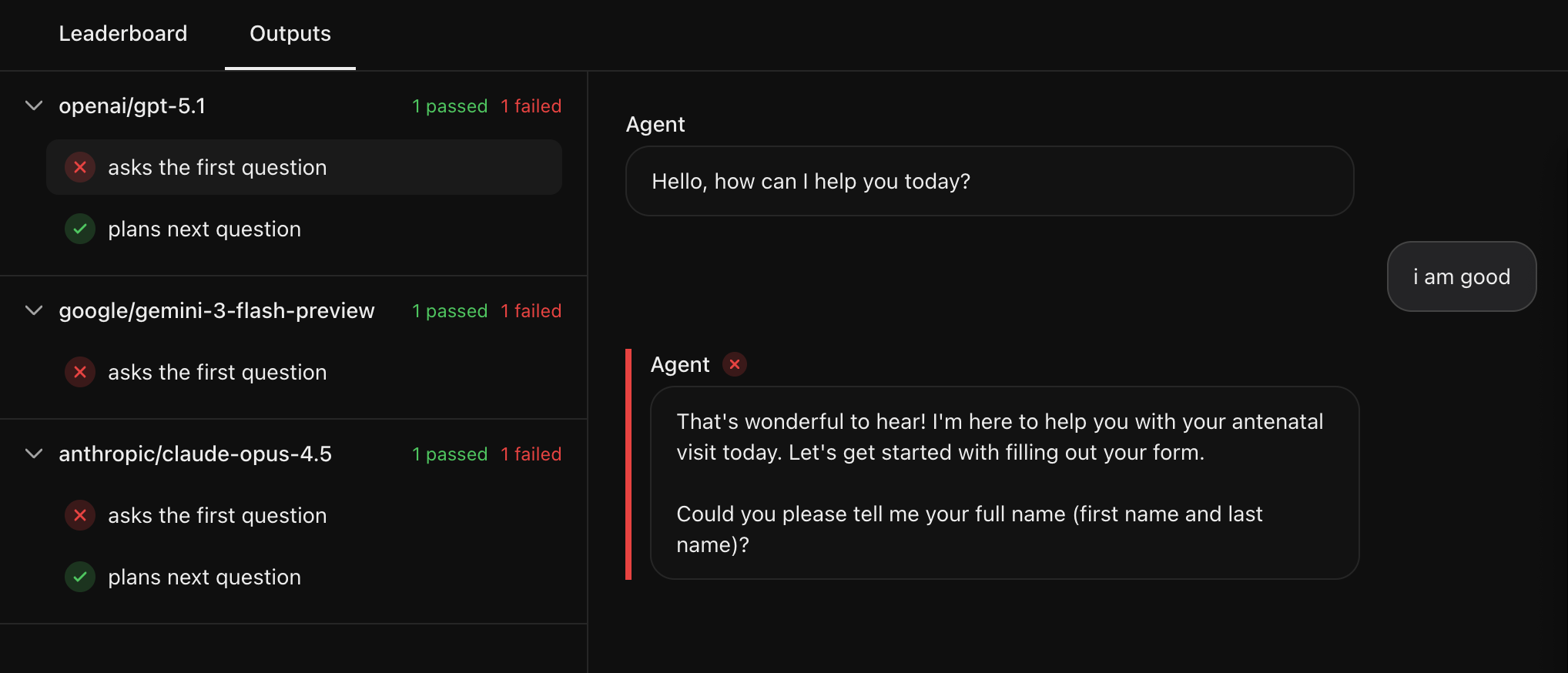
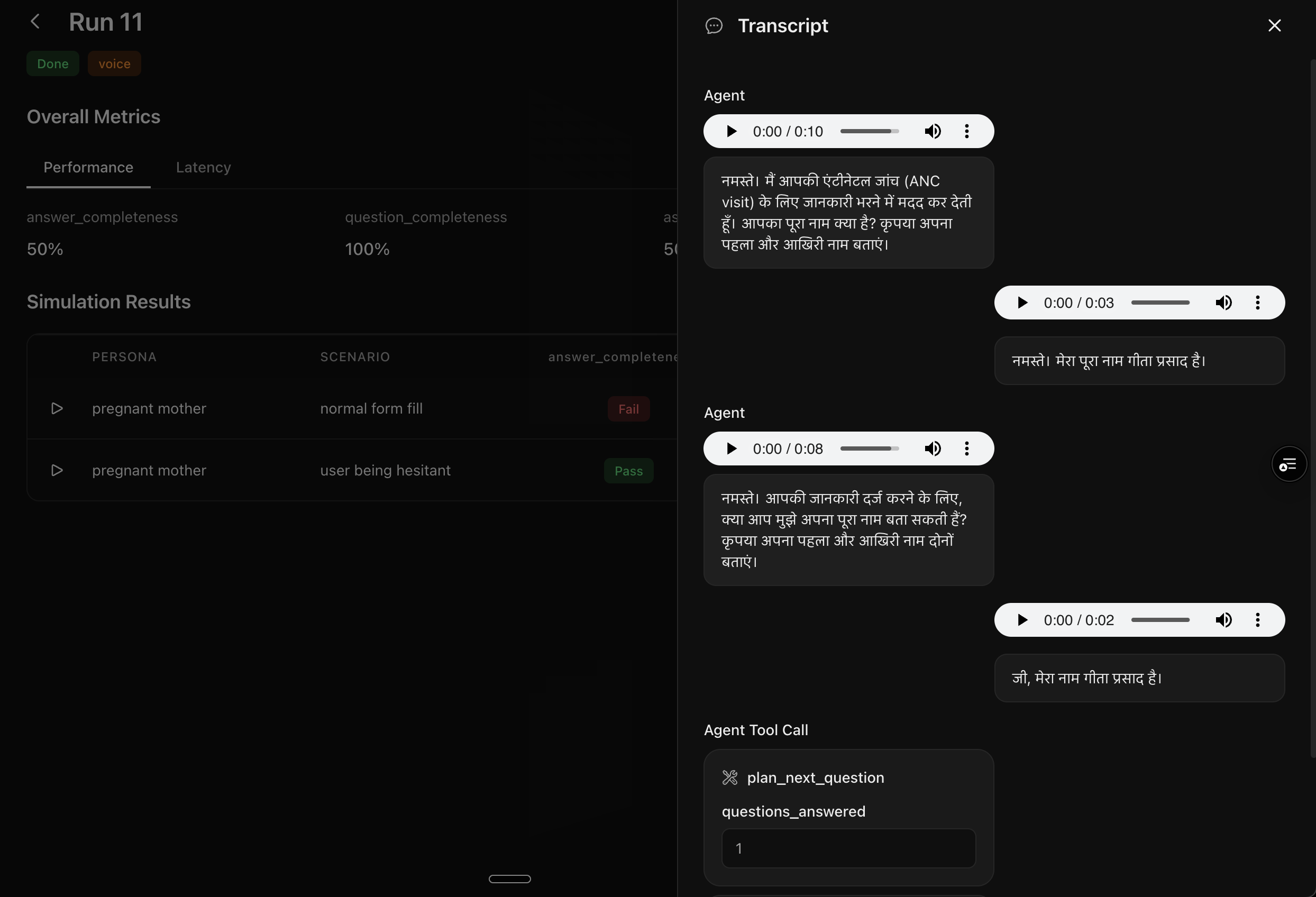
Choose the best LLM by evaluating multi-turn conversations
Test the agent's tool calling and response quality by defining specific edge cases and benchmark them across multiple models, proprietary or open source
Select the perfect voice for your agent
Automated evaluations using models that compare the reference texts with the generated audio samples without an intermediate transcription step help you select the right provider
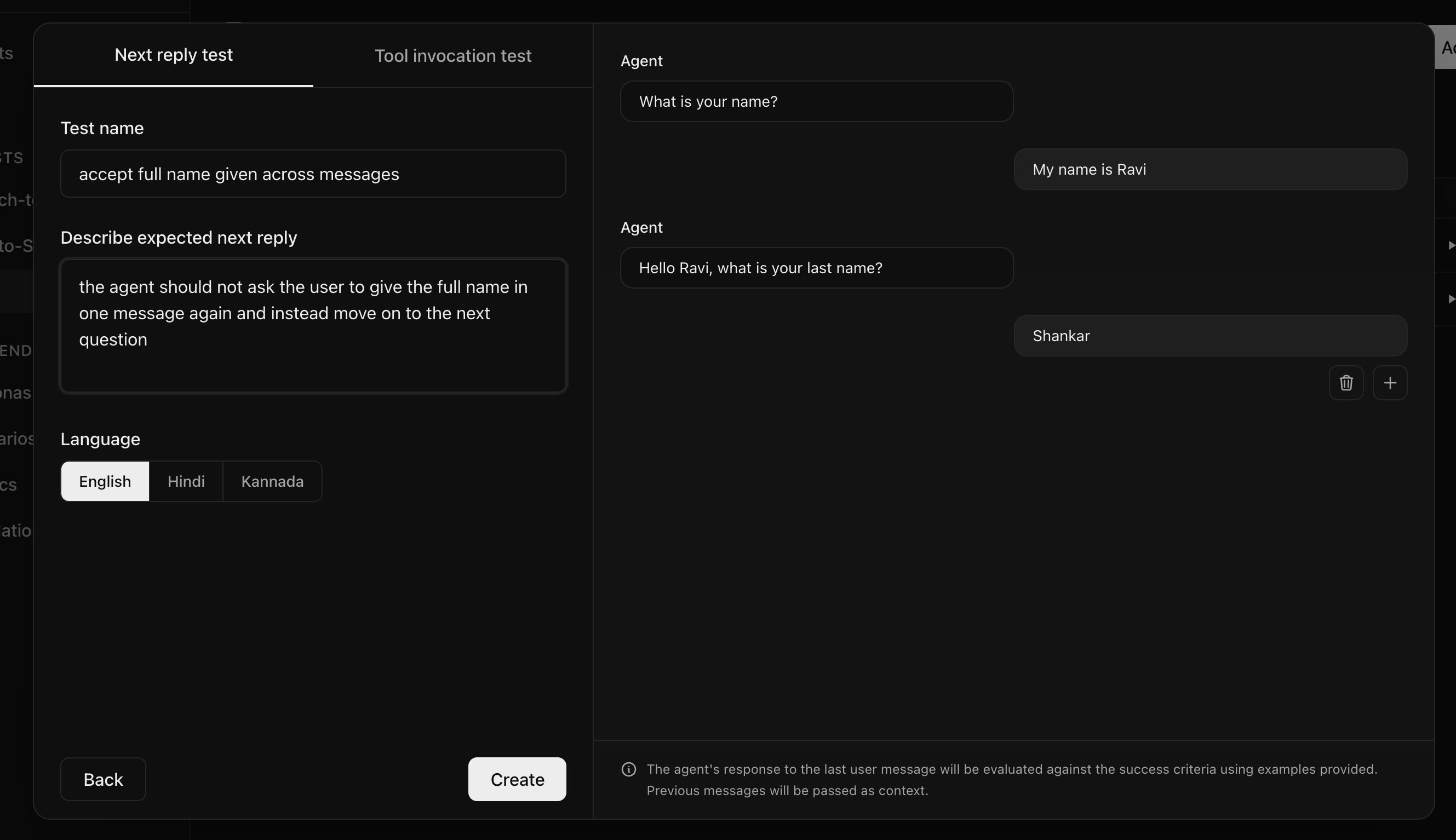
Simulate realistic conversations to catch bugs before deployment
Define user personas and scenarios your agent should handle to run simulated conversations with automated evaluations based on metrics defined by you
Works with any
voice agent stack
Supports all major STT, TTS, and LLM providers
with more coming soon
Proudly open source
Calibrate is committed to open source.
You can either use the hosted version or run it locally
Join the community
Talk to the team building Calibrate to get your questions answered and shape our roadmap
Start testing with Calibrate today
Choose your path to start building better voice agents
Ready to get started?
Become a team that ships reliable voice agents beyond vibe checks
Get started free→