Start a new evaluation
From the sidebar, click on Speech-to-Text to view all your evaluations and datasets. Click the New evaluation button to create a new evaluation.
Add your dataset
On the Dataset tab, choose how to provide your audio samples:
Upload new
Upload new
Create a new dataset inline. Give it a name, then add samples in one of two ways:The

- Add samples inline — Click Upload .wav to attach an audio file and type the reference transcription for each row. Click + Add another sample to add more.
- Bulk upload via ZIP — Upload a ZIP file with the following structure:
data.csv should have two columns:| audio_file | text |
|---|---|
| sample_1.wav | This is the reference transcription for sample 1. |
| sample_2.wav | This is the reference transcription for sample 2. |
| sample_3.wav | This is the reference transcription for sample 3. |
Use existing dataset
Use existing dataset
If you’ve already created a dataset, switch to Use existing dataset to pick from your saved datasets.
Configure settings
Switch to the Settings tab to select the language and the providers you want to compare:
Run evaluation
Click the Evaluate button at the top to start the evaluation. You will be redirected to the results page where you can monitor progress in real-time.View results
Outputs
The Outputs tab shows per-provider results. Select a provider from the list on the left to see its overall metrics and per-sample results.
- Audio — An inline audio player to listen to the original recording
- Ground Truth — The reference transcription you provided
- Prediction — What the STT provider transcribed
- WER — Word Error Rate for that sample
- Similarity — String similarity score
- LLM Judge — Pass/Fail based on semantic evaluation
Leaderboard
The Leaderboard tab shows a side-by-side comparison across all providers with aggregated metrics and bar charts.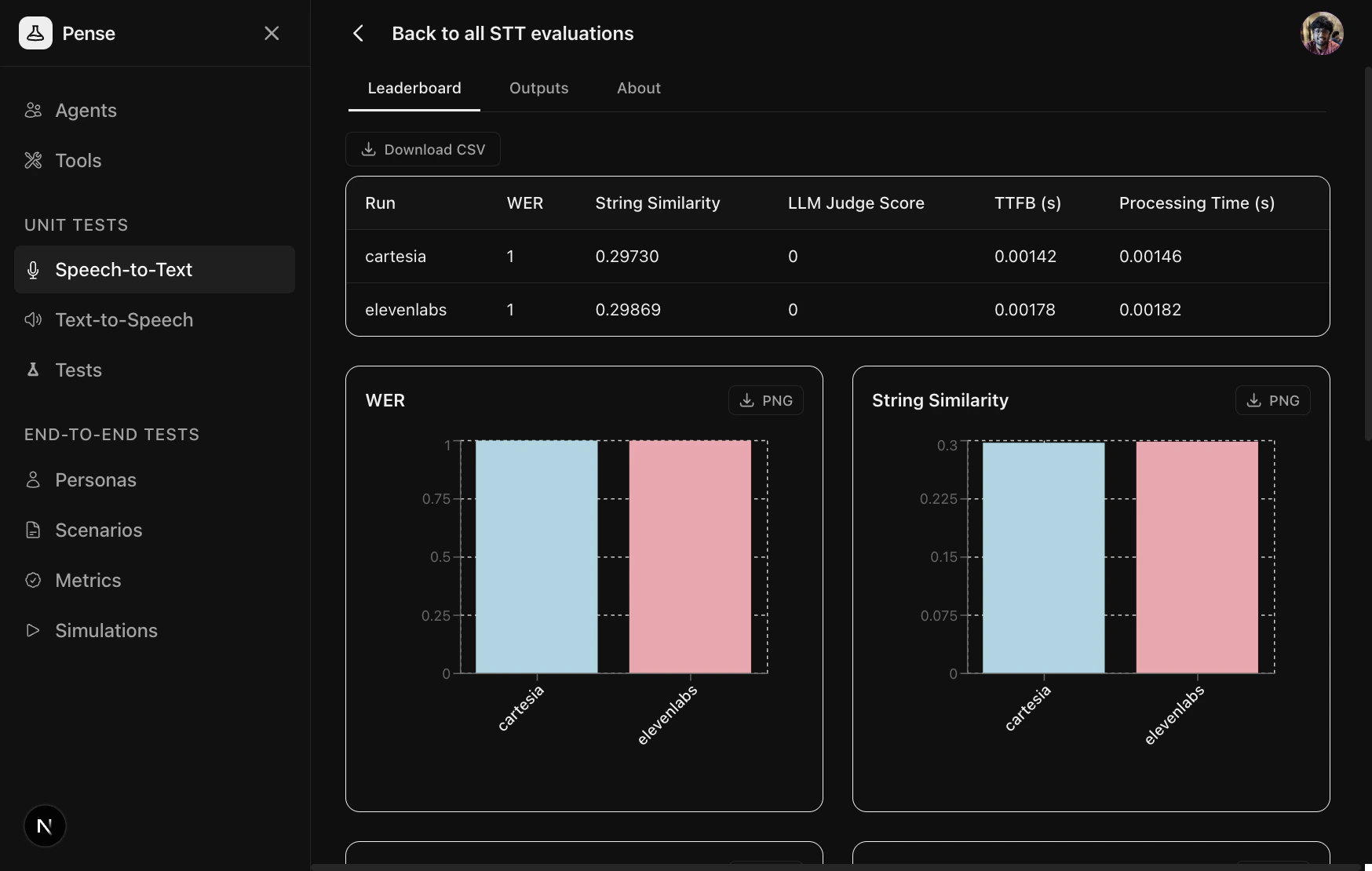
Sharing results publicly
Once your evaluation completes, you can make the results publicly accessible by clicking the Share button on the results page.

Next Steps
Core Concepts
Learn about STT metrics — WER, String Similarity, and LLM Judge
Datasets
Save and reuse evaluation data across multiple evaluations
LLM tests
Find the best LLM for your agent